I know I haven’t posted on this blog for a while, but it’s time for an announcement that needs to be here on this blog as well.
The development release of ModelConverterX does include support for the new Prepar3D v4.4 PBR materials. This means that MCX can now:
- Read the material settings from a P3D v4.4 MDL file
- Write the material settings to a P3D v4.4 MDL/BGL file
- View and edit the material settings in the material editor
The preview image of MCX does not use the PBR settings, so the preview is still as before. For a pure PBR material it will probably look a bit weird. That’s something for a future update.
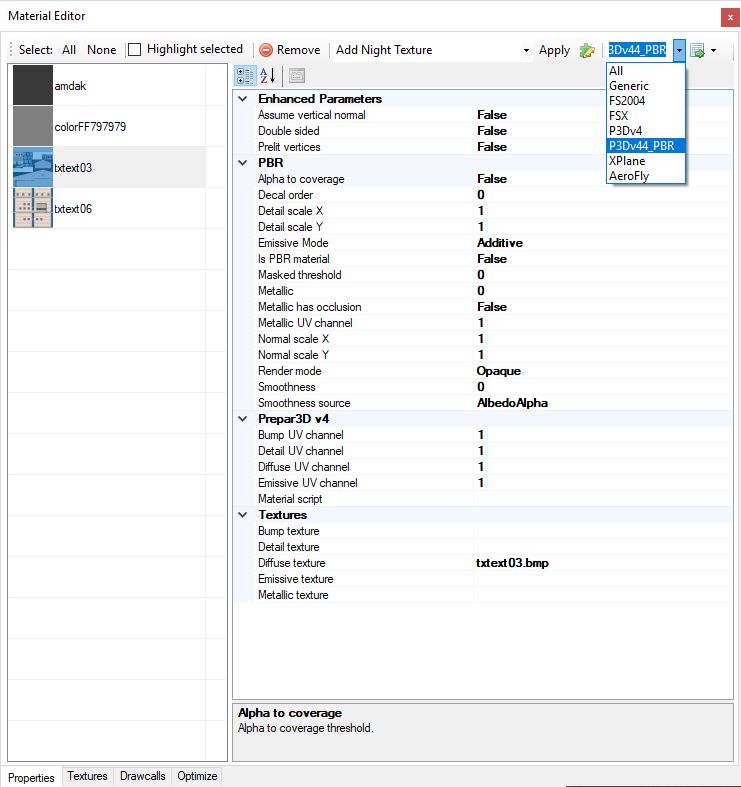
In the material editor I have added a special material view filter that will show you only the PBR related attributes. See the screenshot below. If you want to make a PBR material make sure you set the ‘Is PBR material’ attribute to true, else MCX will export as a normal P3D material.
Another thing you need to be aware of is that MCX can not automatically distinguis between the P3D v4.4 and previous v4 SDKs. This means you might manually have to check if the XtoMDL and BGLComp path for both versions are still correct. You can see them in the options.
Let me know if I forgot anything needed for PBR or if you find other issues. It was quite some refactoring to add this, so I might have broken something else by accident.